타베로그를 크롤링하기4 - 구글 데이터 까보기
- 타베로그를 크롤링하기
- 타베로그를 크롤링하기2 - Google Places API로 비교하기
- 타베로그를 크롤링하기3 - 타베로그 데이터 까보기
- 타베로그를 크롤링하기4 - 구글 데이터 까보기
평점
타베로그 데이터 까보기와 마찬가지로, 구글에서의 평점 분포도 한번 보도록 하겠습니다.
plot_dist(columns=['google_rating'],
labels=['Google'],
colors=['#fdae61'],
include_missing=False,
do_log=[False],
title='Histogram of Google Ratings in Sapporo')
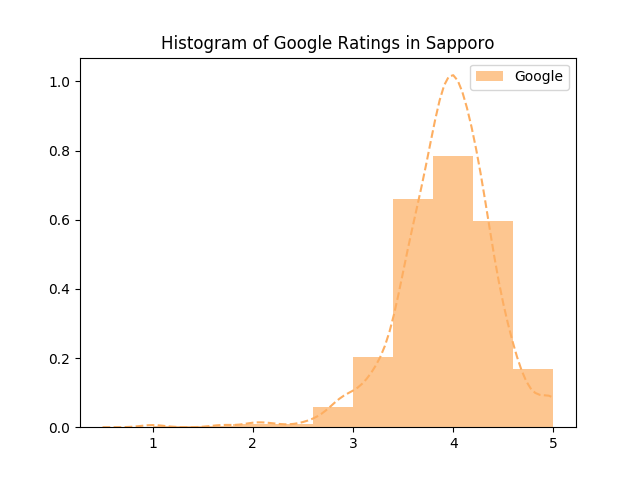
아무래도 리뷰에 참여할 수 있는 사람의 수 자체가 달라서일까요. 평점 0점짜리들만 아니었다면 상당히 정규분포에 가까운 모양이었을 것 같습니다.
평가 갯수
plot_dist(columns=['google_user_ratings_total'],
labels=['Google'],
colors=['#fdae61'],
include_missing=False,
do_log=[False],
title='Histogram of Google Rating Counts in Sapporo')
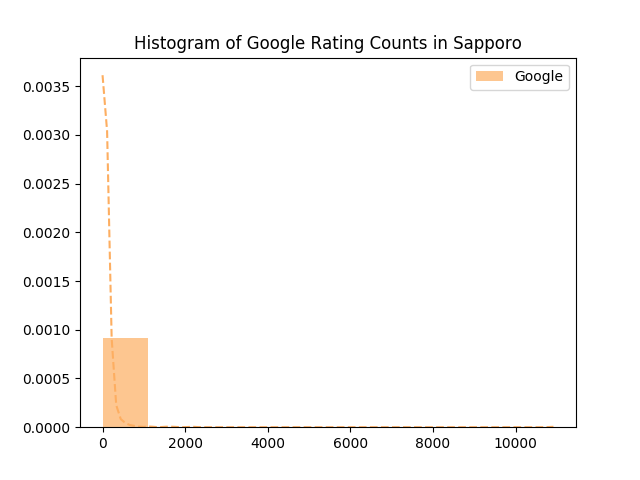
상당히 극단적인 분포를 보여줍니다. 10000건 이상의 리뷰를 받은 식당 때문에 나머지 식당들의 분포를 제대로 파악할 수 없습니다. 이런 경우에는 데이터에 로그를 씌워야 제맛입니다.
plot_dist(columns=['google_user_ratings_total'],
labels=['Google'],
colors=['#fdae61'],
include_missing=False,
do_log=[True],
title='Histogram of Google Rating Counts in Sapporo')
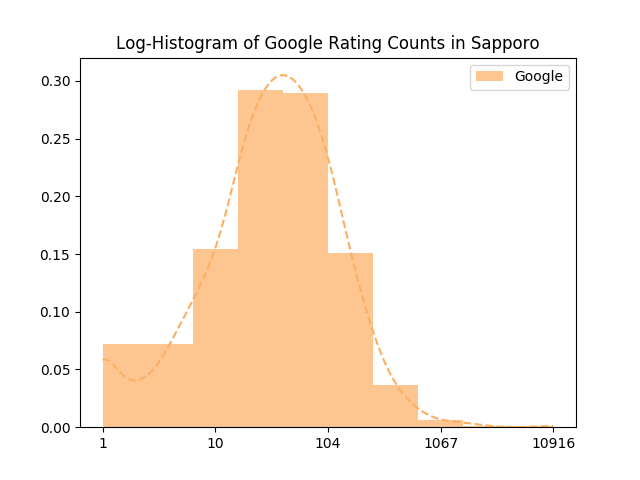
확실히 유저 수가 달라서인지 리뷰의 수도 다른 것 같습니다. 근데 진짜로 10000건 뭘까요. 데이터 오류인 것 같기는 한데 잘 모르겠습니다.
평점과 평가 갯수의 관계
구글 평점과 평가의 갯수 사이의 관계 역시 궁금합니다. 내친김에 영어로 된 리뷰의 갯수도 같이 보면 좋을 것 같습니다. 안타깝게도 리뷰의 갯수는 최대 5개까지밖에 조회를 할 수 없었지만(Google Places Detail API가 5개까지밖에 안 알려줍니다), 그 정보라도 확인해보는 게 좋을 것 같습니다.
plot_scatter(columns=['google_user_ratings_total', 'google_rating', 'google_review_en'],
labels=['Reviews', 'Rating', 'Reviews in English'],
title="Scatterplot of Google's Rating vs Reviews",
log=[True, False, False])
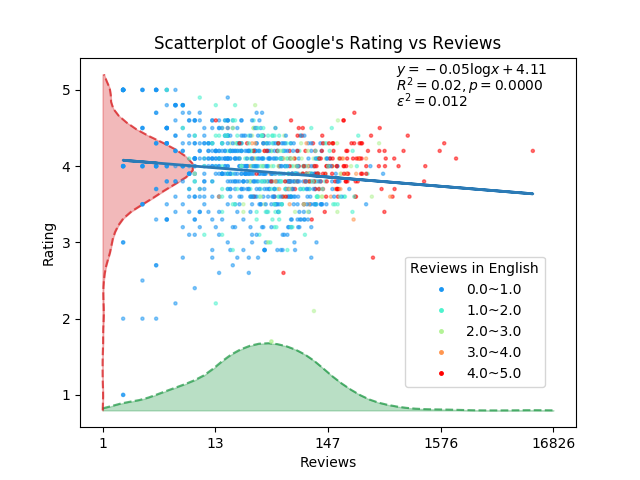
두 변인 간의 상관관계는 거의 찾아볼 수 없는 수준입니다. 하지만, 생각지도 않게 영어로 된 리뷰의 수와 리뷰의 갯수 사이에는 상관관계가 있어보입니다. 조사해보는 것도 재밌을 것 같습니다.
plot_scatter(columns=['google_review_en', 'google_user_ratings_total', ''],
labels=['Reviews', 'Rating', ''],
title="Scatterplot of Google's English Reviews vs Rating",
log=[False, True, False])

아주까지는 아니지만, 꽤나 상관은 있어보입니다. 리뷰어가 많다는 건 외국인들에게도 그만큼 유명한 식당이라는 뜻이려나요.
사이트끼리 분석해보기
이제 드디어 구글과 타베로그를 서로 비교해볼 시간입니다.
plot_scatter(columns=['rating', 'google_rating', ''],
labels=['Tabelog', 'Google', ''],
title="Scatterplot of Ratings (w/o Missing Data)",
log=[False, False, False])
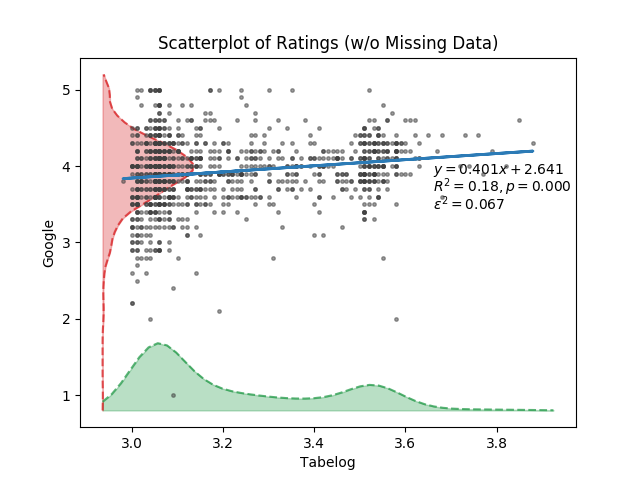
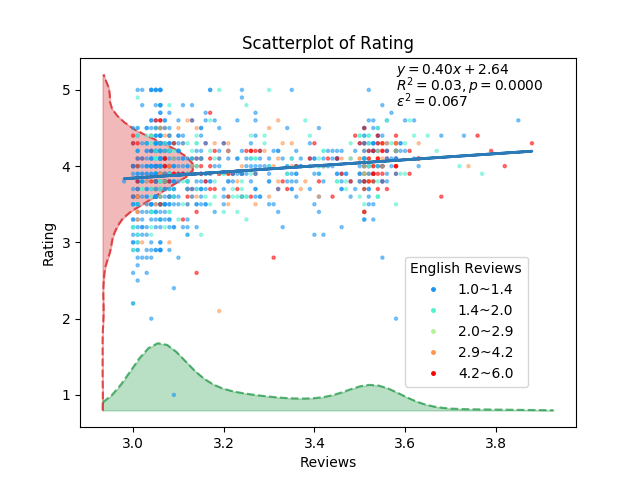
미약하지만 상관관계는 있는 것 같습니다. 구글 평점이 높은 가게가 타베로그에서도 평점이 높은 경향이 있기는 하지만, 법칙 수준은 아닌 것 같습니다. 안타깝게도 제가 수집한 데이터만으로는 그 이유를 설명할 수 없었습니다. 단지 그래프로 확인했던 건, 타베로그에서 3.5점 정도의 식당들, 즉 소위 ‘맛집’으로 분류할 수 있는 식당들이라면 영어로 된 평가가 꽤 많았다는 것 정도였습니다.
결론
데이터를 통해 다음과 같은 사실들을 확인할 수 있었습니다.
- 타베로그에서 삿포로의 맛집을 검색하면 평점은 거의 대부분 3점대이다
- 타베로그에서 삿포로의 음식점들은 3.2점 이상이면 훌륭할 것이다
- 타베로그에서는 평가의 갯수는 기대 안 하는 게 좋다
- 타베로그라면 평가의 갯수와 평점은 비례할 수 있지만, 구글이라면 아니다
- 구글과 타베로그의 평가는 서로 엇비슷하긴 하지만, 절대적이지는 않다
이번 프로젝트에는 한계도 많았습니다. 먼저, 연구 지역이 삿포로로 한정되어 있었고, 저녁시간대의 식당들 위주로 검색을 해서 연구 대상 집단에 한계가 있었습니다. 둘째로, 타베로그에서 크롤링할 수 있었던 데이터의 양이 적어서, 전체 집단을 대표하는지도 의문입니다. 타베로그가 랜덤하게 뽑은 60페이지를 돌려줬다면 좋았겠지만, 개발자인 저도 그런 식의 구현을 했을 것이라고는 전혀 기대할 수 없군요. 셋째로, Google Places API를 통해 얻은 데이터가 진짜 그 식당의 데이터인지 검증을 전혀 하지 못했습니다. 나름대로 검사 로직을 만들어놓기는 했습니다만, 엉성한 로직이라 제대로 된 데이터가 수집되었는지는 스스로도 의문입니다. 이 부분은 고쳐나갈 부분이 되겠군요.